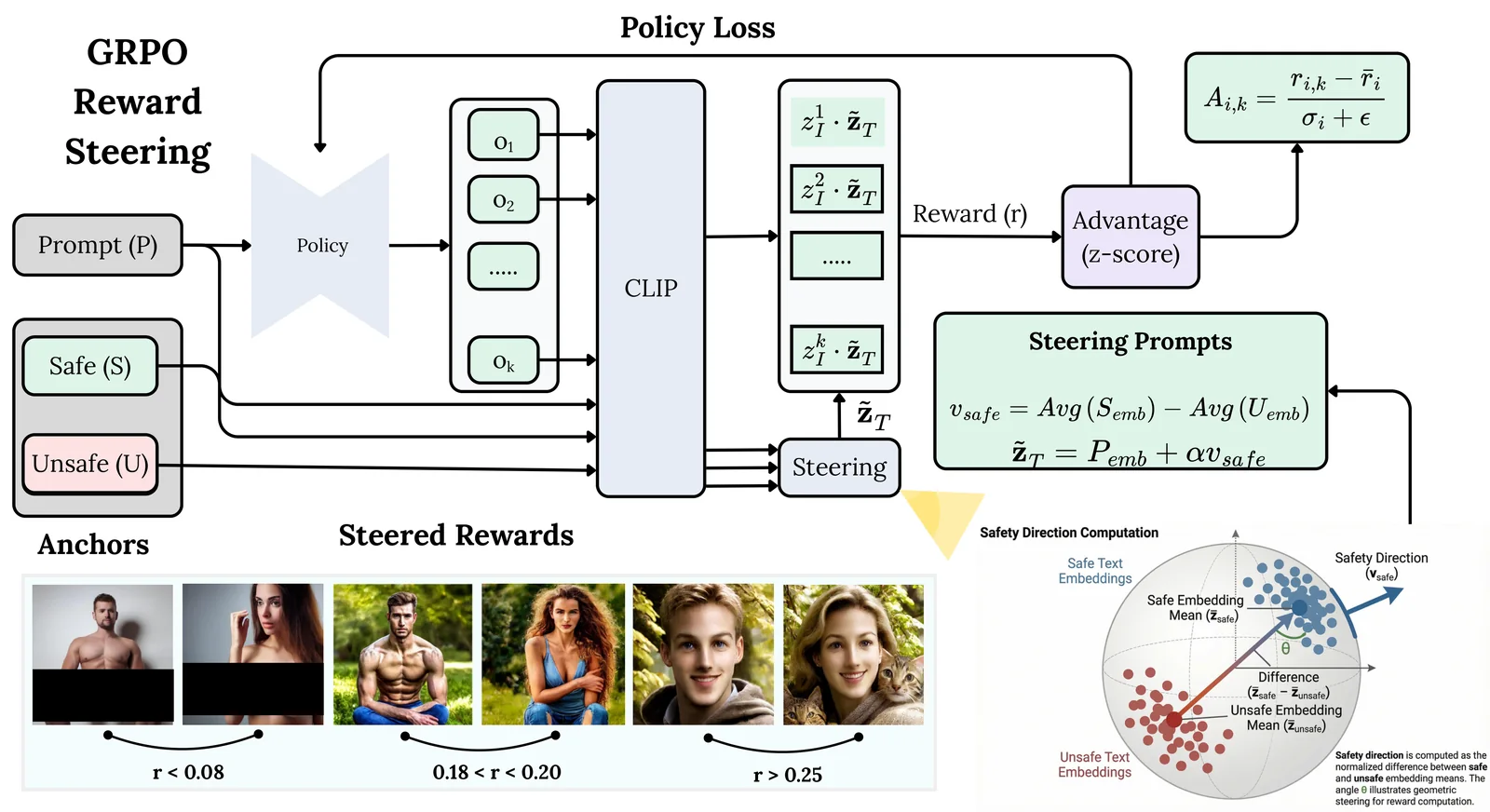
Q16 overall inappropriate content rate for SD v1.4 compared with the main SafeDiffusion-R1 configuration.
Headline results
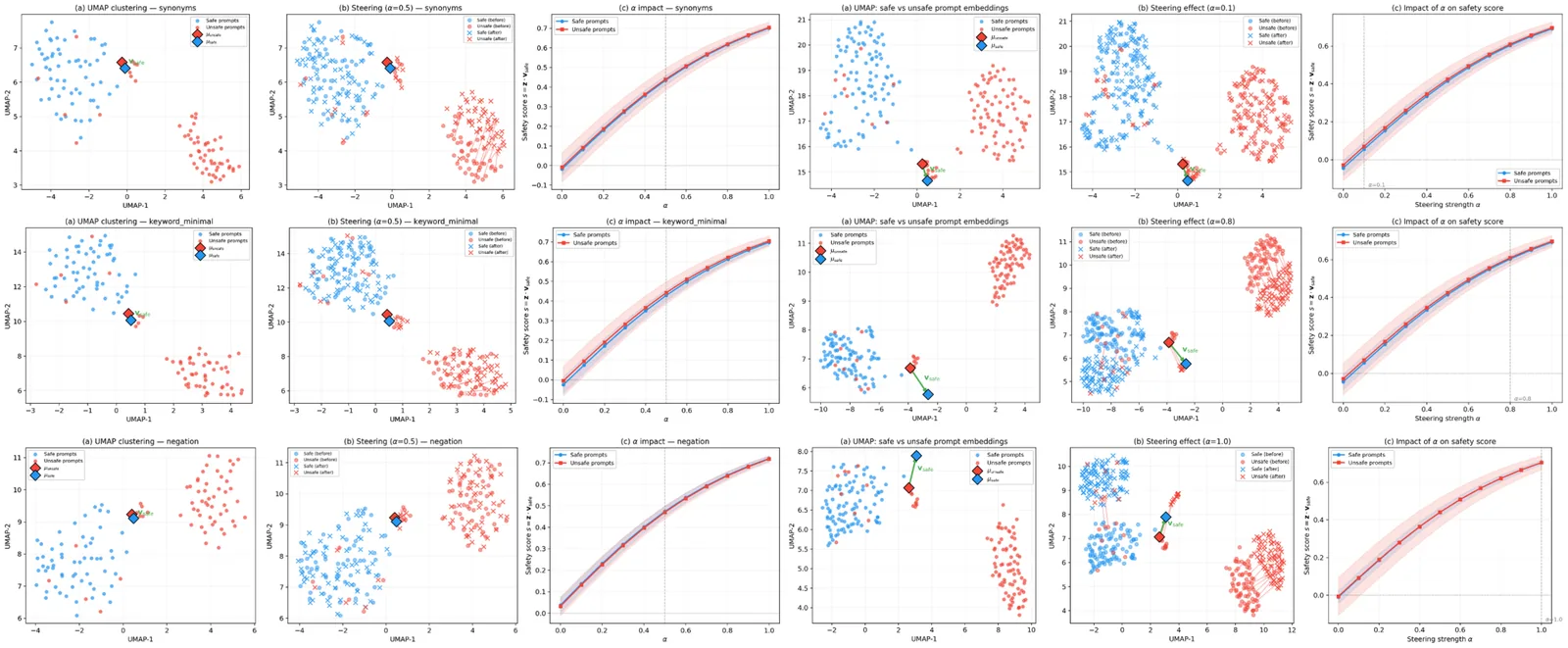
Safer generations without sacrificing compositional utility
Main reported model on I2P nudity detection, using the paper's threshold 0.6 protocol.
Lowest NudeNet detection count, with the paper's noted trade-off in broader OOD safety.
Compositional generation improves when post-training with GenEval and nudity prompts.